Od 3 kwietnia 2026 roku polskie podmioty kluczowe i ważne mają zaledwie 24 godziny na zgłoszenie poważnego incydentu cyberbezpieczeństwa od momentu jego wykrycia. Tak krótki termin oznacza, że organizacja musi już wcześniej wiedzieć, jakie zagrożenia jej dotyczą, które aktywa są krytyczne i kto podejmuje decyzje w pierwszych godzinach po ataku. Ocena ryzyka i reagowanie na incydenty muszą tworzyć jeden cykl prowadzony spójnie w całej organizacji. W tym artykule omawiamy, jak ułożyć taki cykl krok po kroku.
Wprowadzenie do oceny ryzyka i reagowania na incydenty
Wiele firm prowadzi ocenę ryzyka i reakcję na incydenty jako oddzielne procesy. Zespół zarządzania ryzykiem lub compliance opiekuje się rejestrem ryzyk i raz w roku przedstawia go zarządowi. Dział IT zajmuje się bieżącymi incydentami i pracuje na własnych procedurach. Te dwa nurty rzadko się przecinają. Zarządzający ryzykiem nie wiedzą, jakie ataki naprawdę zdarzyły się w ostatnim kwartale, a IT nie zagląda do rejestru ryzyk i nie wie, które aktywa zostały oznaczone jako krytyczne. W rezultacie ten sam typ incydentu bezpieczeństwa potrafi się powtórzyć kilka razy, zanim ktokolwiek dostrzeże wzorzec.
Tymczasem ocena ryzyka i reagowanie na incydenty są dwoma etapami tego samego cyklu. Każdy incydent powinien aktualizować rejestr ryzyk, a każde nowo zidentyfikowane ryzyko powinno trafiać do procedur zespołu obsługującego incydenty. Bez tego sprzężenia organizacja uczy się powoli, a zarząd dostaje niespójne sygnały od dwóch zespołów, które patrzą na to samo bezpieczeństwo z różnych pozycji.
Jak zidentyfikować aktywa w organizacji?
Zanim organizacja zacznie analizować ryzyka, musi mieć pełną listę zasobów wymagających ochrony. Tę listę trzeba regularnie odświeżać, bo środowisko IT i procesy biznesowe zmieniają się szybciej, niż większość firm to zauważa. Standardowo wyróżnia się pięć typów aktywów. Najwięcej uwagi zespoły bezpieczeństwa poświęcają aktywom informacyjnym, czyli danym oraz dokumentacji.
| Kategoria aktywów | Przykłady | Kto zarządza |
| Informacyjne | Bazy danych klientów, dokumentacja techniczna, kod źródłowy | Właściciel procesu |
| Techniczne (IT) | Serwery, aplikacje, sieć, środowiska chmurowe | Dział IT |
| Fizyczne | Serwerownia, sprzęt końcowy, nośniki danych | Administracja, IT |
| Ludzkie | Role krytyczne, eksperci, administratorzy | HR, kierownicy działów |
| Procesowe | Obsługa reklamacji, produkcja, rozliczenia | Właściciel procesu |
Standardy zarządzania, w tym ISO 27001, dopuszczają różne sposoby grupowania aktywów. Najważniejsze jest, by każda pozycja w rejestrze miała przypisanego właściciela, który potwierdza zmiany w wypadku istotnej rekonfiguracji, zmianach biznesowych lub technicznych. . Bez tego dane szybko się dezaktualizują.
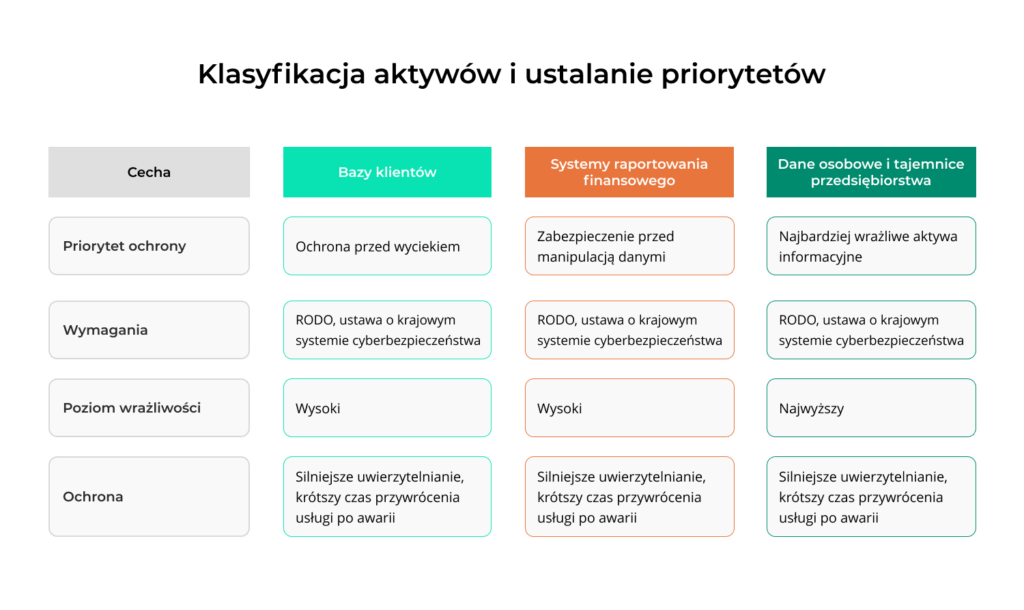
Klasyfikacja aktywów i ustalanie priorytetów
Klasyfikacja aktywów polega na tym, że zespół bezpieczeństwa ocenia, w jakim stopniu każdy zasób potrzebuje ochrony. Najczęściej korzysta się w tym celu z triady CIA, czyli oceny poufności (confidentiality), integralności (integrity) oraz dostępności (availability) każdego zasobu. Bazy klientów potrzebują przede wszystkim ochrony przed wyciekiem, a systemy raportowania finansowego zabezpieczenia przed manipulacją danych. W klasyfikacji uwzględnia się również wymagania RODO oraz ustawy o krajowym systemie cyberbezpieczeństwa wdrażającej NIS2. Dane osobowe i tajemnice przedsiębiorstwa są zaklasyfikowane jako najbardziej wrażliwe aktywa informacyjne.
Po klasyfikacji organizacja dobiera konkretne zabezpieczenia. Większość firm posługuje się skalą o trzech albo czterech poziomach wrażliwości, od informacji publicznych do ściśle poufnych. Im wyższy poziom, tym mocniejsza ochrona, czyli silniejsze uwierzytelnianie i krótszy czas przywrócenia usługi po awarii (krótsze wartości RTO i RPO). Pozostałe zasoby chroni standardowy zestaw zabezpieczeń całej organizacji. Takie rozróżnienie pomaga odpowiednio wyważyć koszt i zakres ochrony.
Proces oceny ryzyka krok po kroku
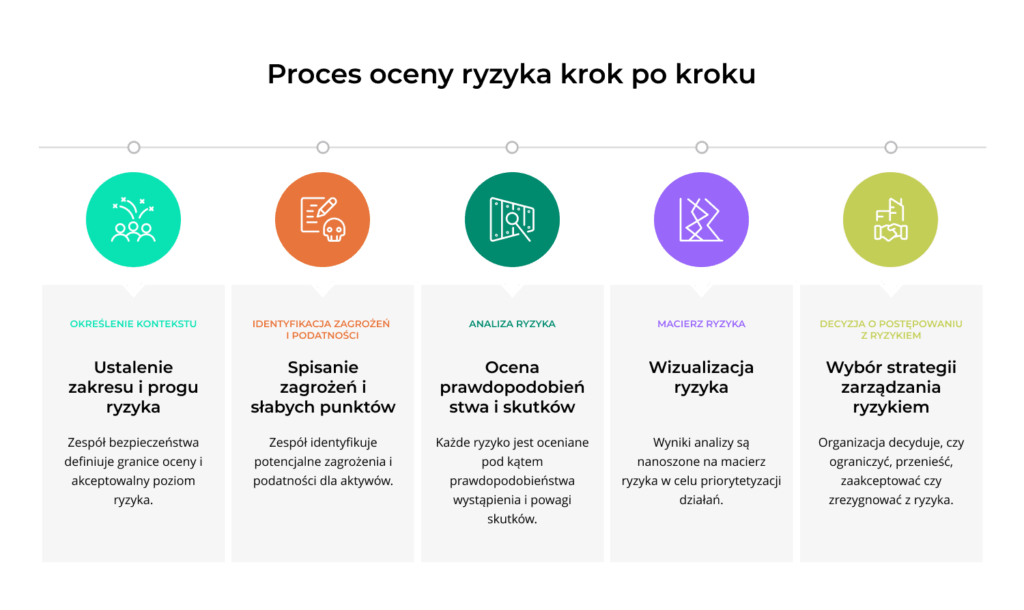
Po sklasyfikowaniu aktywów wiadomo, które z nich wymagają największej ochrony. Ocena ryzyka pomaga ustalić, w jakiej kolejności trzeba się tym zająć. Standardowo proces oceny przebiega w pięciu krokach.
1. Określenie kontekstu
Zanim zespół bezpieczeństwa zacznie identyfikować zagrożenia, musi ustalić zakres oceny oraz próg akceptacji ryzyka. Bez tych ustaleń trudno porównać wyniki kolejnych ocen.
2. Identyfikacja zagrożeń i podatności
W tym kroku zespół spisuje zagrożenia, które mogą dotknąć poszczególne grupy aktywów. Najczęstsze z nich w zakresie cyberbezpieczństwa informacji to phishing oraz ransomware, ale też działania wewnętrznego sprawcy. Podczas tworzenia listy zagrożeń można wykorzystać informacje dostępne w normie ISO/IEC 27005 i corocznym raporcie ENISA Threat Landscape.
3. Analiza ryzyka
Każde zagrożenie ocenia się pod kątem prawdopodobieństwa jego wystąpienia oraz powagi skutków dla organizacji. W bankowości i ubezpieczeniach częściej stosuje się metody ilościowe, takie jak FAIR (ang. Factor Analysis of Information Risk), które wyrażają ryzyko w wartościach pieniężnych. Pozostałe branże korzystają z podejścia jakościowego, w którym ocena ryzyka opiera się na doświadczeniu ekspertów oraz danych z wcześniejszych incydentów.
4. Macierz ryzyka
Wyniki analizy nanosi się na macierz ryzyka. Oś pionowa wyraża prawdopodobieństwo wystąpienia danego ryzyka, a oś pozioma jego skutki. Ryzyka o wysokim prawdopodobieństwie i poważnych skutkach wymagają natychmiastowych działań, a te mało prawdopodobne i których skutki nie są dotkliwe, można świadomie zaakceptować.
5. Decyzja o postępowaniu z ryzykiem
Organizacja może ograniczać ryzyko przez kontrole, przenieść je na stronę trzecią poprzez ubezpieczenie albo formalnie zaakceptować. Czasem najwłaściwszą może być rezygnacja z określonej działalności.
Wynikiem oceny jest zaktualizowany rejestr i plan postępowania. Oba dokumenty stają się punktem odniesienia dla kontroli oraz reagowania na incydenty.
Jak projektować i wdrażać kontrole bezpieczeństwa?
Norma ISO/IEC 27002 z 2022 roku dzieli kontrole bezpieczeństwa na trzy kategorie funkcjonalne. Ten podział dobrze oddaje cały cykl, prowadząc od zapobiegania, przez wykrywanie, po reakcję.
Kontrole prewencyjne
Zadaniem kontroli prewencyjnych jest zapobieganie incydentom, zanim do nich dojdzie. Kluczowe jest tu wieloskładnikowe uwierzytelnianie oraz ścisłe zarządzanie uprawnieniami pracowników na każdym etapie zatrudnienia. Równie ważna jest segmentacja sieci, która izoluje od siebie systemy, oraz ich utwardzanie (ang. hardening), czyli usuwanie luk w konfiguracji urządzeń. Niezbędną ochronę zapewnia także szyfrowanie danych podczas ich przechowywania oraz przesyłania.
W dobie regulacji NIS2 coraz większe znaczenie ma warstwa organizacyjna, czyli szkolenia oraz nadzór nad bezpieczeństwem dostawców IT, którzy często stają się celem ataku. Skuteczność tych działań zależy jednak od bieżącego aktualizowania list uprawnień i polityk haseł. Nieużywane procedury lub nieaktualne zasady dają zarządowi jedynie złudne poczucie bezpieczeństwa.
Kontrole detekcyjne
Ponieważ nie da się zapobiec każdemu atakowi, druga warstwa zabezpieczeń służy do jak najszybszego wykrywania incydentów. Standardem jest tu system SIEM (ang. Security Information and Event Management), który gromadzi cyfrowe ślady z całej sieci, łączy je w logiczną całość i alarmuje zespół o wszelkich nieprawidłowościach. Monitoring uzupełniają systemy klasy IDS (ang. Intrusion Detection System) oraz IPS (ang. Intrusion Prevention System), które potrafią nie tylko rozpoznawać próby włamań, ale też automatycznie je blokować. Detekcja opiera się na analizie znanych wzorców ataków lub nietypowych zachowań, które odbiegają od codziennej normy.
Kontrole korygujące
Gdy systemy wykryją zagrożenie, uruchamiane są kontrole korygujące, których celem jest przywrócenie organizacji do normalnego stanu działania. Obejmują one procedury reagowania, plany odtworzeniowe oraz mechanizmy izolacji zaatakowanych systemów, a także wykorzystanie kopii zapasowych. Skuteczność tej warstwy sprawdza się poprzez regularne testy przywracania danych oraz symulacje incydentów. Prawdziwy atak ransomware to najgorszy możliwy moment na odkrycie, że kopia zapasowa była niekompletna lub nie zadziałała.
Narzędzia monitoringu i detekcji incydentów
Narzędzia monitoringu bezpieczeństwa stanowią trzon zdolności detekcyjnej organizacji. Są one źródłem danych dla zespołu reagującego i dostarczają ślad dowodowy niezbędny do raportowania po incydencie zgodnie z wymogami NIS2.
Kluczowym rozwiązaniem w tym obszarze jest system SIEM, który zbiera logi z systemów oraz urządzeń sieciowych, koreluje je według reguł i prezentuje w jednym miejscu. Bez niego monitoring bezpieczeństwa rozprasza się na wiele osobnych konsol, a analityk nie ma szansy zobaczyć całego kontekstu zdarzenia. Sam SIEM jednak nie wystarczy, ponieważ bez dobrze zdefiniowanych reguł i sprawnego procesu obsługi generuje on setki alertów dziennie, stając się jedynie źródłem szumu.
Pozostałe rozwiązania to klasy narzędzi sieciowych. IDS wykrywa próby ataku na poziomie sieci lub hosta i raportuje je do zespołu bez ingerowania w sam ruch. IPS idzie o krok dalej i automatycznie blokuje wykryty ruch, zanim dotrze on do celu. Obecnie standardem na styku sieci wewnętrznej z internetem jest system IDPS (ang. Intrusion Detection and Prevention System), który łączy obie te funkcje. Dobór konkretnego narzędzia zależy od architektury sieci oraz profilu ryzyka, a w środowisku produkcyjnym także od tolerancji na fałszywe alarmy.
Proces reagowania na incydenty
Skuteczne działania naprawcze planuje się z dużym wyprzedzeniem. Dobrze przygotowana strategia, precyzyjnie rozdzielone role oraz regularnie weryfikowane procedury sprawiają, że monitoring spełnia swoją funkcję i realnie wspiera organizację w kryzysie. Istotnym elementem jest dbałość o ślady dowodowe, takie jak cyfrowe logi czy obrazy zaatakowanych dysków. Zabezpieczenie tych danych w momencie wystąpienia ataku pozwala rzetelnie ustalić przyczyny zdarzenia i ułatwia rozliczenie odpowiedzialności przed sądem lub organem nadzoru. Właściwie opracowana instrukcja wskazuje konkretne osoby odpowiedzialne za ochronę dowodów jeszcze przed rozpoczęciem przywracania usług.
Samą obsługę incydentu warto oprzeć na sprawdzonym modelu składającym się z sześciu etapów. Pierwszy z nich to przygotowanie, które polega na zebraniu niezbędnych narzędzi i wyznaczeniu kompetentnych osób do konkretnych zadań. Następnie zespół przechodzi do detekcji i analizy, rozpoznając rodzaj zagrożenia oraz szacując jego wpływ na firmę. Kolejny krok to ograniczanie skutków poprzez izolację zainfekowanych systemów, po czym następuje usuwanie źródła problemu, na przykład złośliwego oprogramowania lub przejętych haseł. Piąty etap obejmuje bezpieczne przywrócenie usług i kontrolę, czy systemy działają poprawnie. Cały cykl kończy się wyciągnięciem wniosków, co pozwala na aktualizację rejestru ryzyk oraz ewentualną zmianę dotychczasowych zabezpieczeń.
Sprawna realizacja tych faz jest o tyle istotna, że regulacje takie jak NIS2 nakładają na organizacje rygorystyczne terminy raportowania incydentów – pierwsze ostrzeżenie musi trafić do organów nadzorczych już w ciągu 24 godzin.
Integracja z normami ISO 27001, ISO 22301 i dyrektywą NIS2
Zarządzanie ryzykiem oraz reagowanie na incydenty nie powinny funkcjonować w izolacji. Największą skuteczność osiągają wtedy, gdy stają się elementem spójnego systemu opartego na uznanych standardach. Norma ISO 27001 kładzie nacisk na systemowe podejście do ochrony informacji, w którym ocena ryzyka determinuje wybór odpowiednich zabezpieczeń. Z kolei dyrektywa NIS2 narzuca konkretne obowiązki w zakresie odporności podmiotów kluczowych, wymagając nie tylko ochrony, ale też sprawnego zarządzania ciągłością działania.
W tym miejscu istotne okazuje się powiązanie z normą ISO 22301, która koncentruje się na zdolności organizacji do przetrwania sytuacji kryzysowych. Połączenie tych standardów pozwala uniknąć powielania procedur i zapewnia lepszy przepływ informacji. Przykładowo, analiza wpływu na biznes (BIA) z obszaru ciągłości działania powinna zasilać proces oceny ryzyka IT, a plany odtworzeniowe po ataku ransomware muszą być spójne z ogólną strategią kryzysową firmy. Takie holistyczne podejście sprawia, że bezpieczeństwo przestaje być jedynie działaniem technicznym, a staje się integralną częścią zarządzania całą organizacją.
Najczęstsze błędy i wyzwania
Wdrażanie mechanizmów bezpieczeństwa rzadko przebiega bez zakłóceń, a zapewnienie ich stałej efektywności bywa trudne. Do najczęstszych problemów należą:
- Rejestr ryzyk funkcjonujący w izolacji
Dokument ten często pozostaje martwym plikiem, do którego zagląda się raz w roku przed audytem, a zespół reagujący na incydenty w ogóle z niego nie korzysta. - Nadmiar dokumentacji
Polityki bezpieczeństwa mają niekiedy ponad sto stron, przez co nikt nie potrafi wskazać, kto faktycznie odpowiada za incydenty w środowisku produkcyjnym. - Dobór kontroli pod audyt
Głównym kryterium doboru zabezpieczeń bywa wyłącznie dopasowanie do wymogów kontrolerów. Poziom zabezpieczeń powinien jednak wynikać bezpośrednio z przeprowadzonej oceny ryzyka. - Brak testów planów reagowania
Procedura może być napisana, ale jeśli nie zostanie przećwiczona, może okazać się, że w warunkach kryzysowych nie spełnia swojej funkcji. - Rozwarstwienie odpowiedzialności
Rejestr ryzyk często pozostaje w rękach działu IT lub zespołu zarządzającego ryzykiem lub compliance, zamiast znajdować się pod nadzorem właściciela procesu biznesowego. To właśnie on ponosi konsekwencje pojawienia się zagrożenia, więc bez jego udziału rejestr staje się jedynie dokumentem technicznym.

Powyższe błędy sprawiają, że systemy bezpieczeństwa działają jedynie w teorii. Dopiero wyeliminowanie tych barier pozwala na realne powiązanie procedur z codzienną praktyką operacyjną firmy.
Podsumowanie i dobre praktyki
Budowa odporności organizacji to proces ciągły, który wymaga wyjścia poza schematyczne wypełnianie list kontrolnych. Skuteczna ochrona zaczyna się od rzetelnej klasyfikacji aktywów i systematycznej oceny ryzyka, co pozwala świadomie dobierać kontrole bezpieczeństwa tam, gdzie są one najbardziej potrzebne. Integracja standardów ISO 27001, ISO 22301 oraz wymogów NIS2 służy stworzeniu środowiska, w którym technologia, dopracowane procedury i świadomi pracownicy współpracują w celu minimalizacji skutków incydentów. Najlepszą praktyką pozostaje regularne testowanie planów reagowania oraz angażowanie właścicieli procesów biznesowych w decyzje dotyczące ryzyka, co zamienia teoretyczną dokumentację w realną tarczę ochronną firmy.








